

This post in the Data Cloud Primer series explains the data harmonization process in Salesforce Data Cloud.
Data Cloud accepts data from a variety of sources. Harmonization refers to the process of transforming (or modeling) different data sources into one. Once data has been unified (or harmonized) into a standardized data model, it can then be used for insights, segmentation and activation.
Data Dictionary
The first step in data harmonization is to map the source data. Poorly considered choices at this stage can result in inconsistencies and worse still, incorrect data in downstream processes. In order to mitigate this risk, it is recommended to create a data dictionary for each data source prior to implementing data mapping.
A data dictionary defines the data entities, attributes, context, and allowable values. Creating a dictionary for each data source not only enables a data mapping specification to be determined, but will also identify common attributes across data sources and how (or if) they relate to each other. Once data dictionaries have been defined, the data can be mapped.
DMO Concepts
In Data Cloud, mapping occurs between the DLO and DMO (refer to previous post for data model concepts). It’s important to stress that Data Cloud is not a ‘bring your own’ data model. For example, unlike Marketing Cloud, which allows users to create their own schemas and relationships in Data Extensions, Data Cloud uses a highly canonical data model consisting of 89 (and counting) pre-defined models, or ‘DMOs’ to accommodate for the vast majority of platform use cases. Additionally, as also mentioned in the previous post, standard DMOs can be extended by adding custom fields and objects to create a hybrid model approach. However, it is recommended to identify applicable standard DMOs and fields where possible, and only extend the model with custom fields and objects where necessary.
While several Data Cloud DMOs may appear to be similar to Salesforce standard objects — for example Individual, Account, and Case — these objects are not the same. They may semantically express the same item, but they are conceptually very different.
Field Mapping
Mapping DSO fields to DMO fields in Data Cloud is a straightforward process and is achieved through an intuitive interface. As discussed in the previous post, When creating a data stream, you must select a category or type of data found in that data stream; either Profile, Engagement, or Other. Correct category assignment is important, as it can’t be changed after the data stream is created. Categories are also assigned to DMOs and are inherited from the first DLO mapped to it, where the DMO will only allow mapping of the same DLO category that was first assigned to it. While categories are generally chosen by the user, there are some exceptions, for example the Individual DMO will always use the profile category. Additionally, data sources from Salesforce Connectors enforce default mappings which can’t be changed.
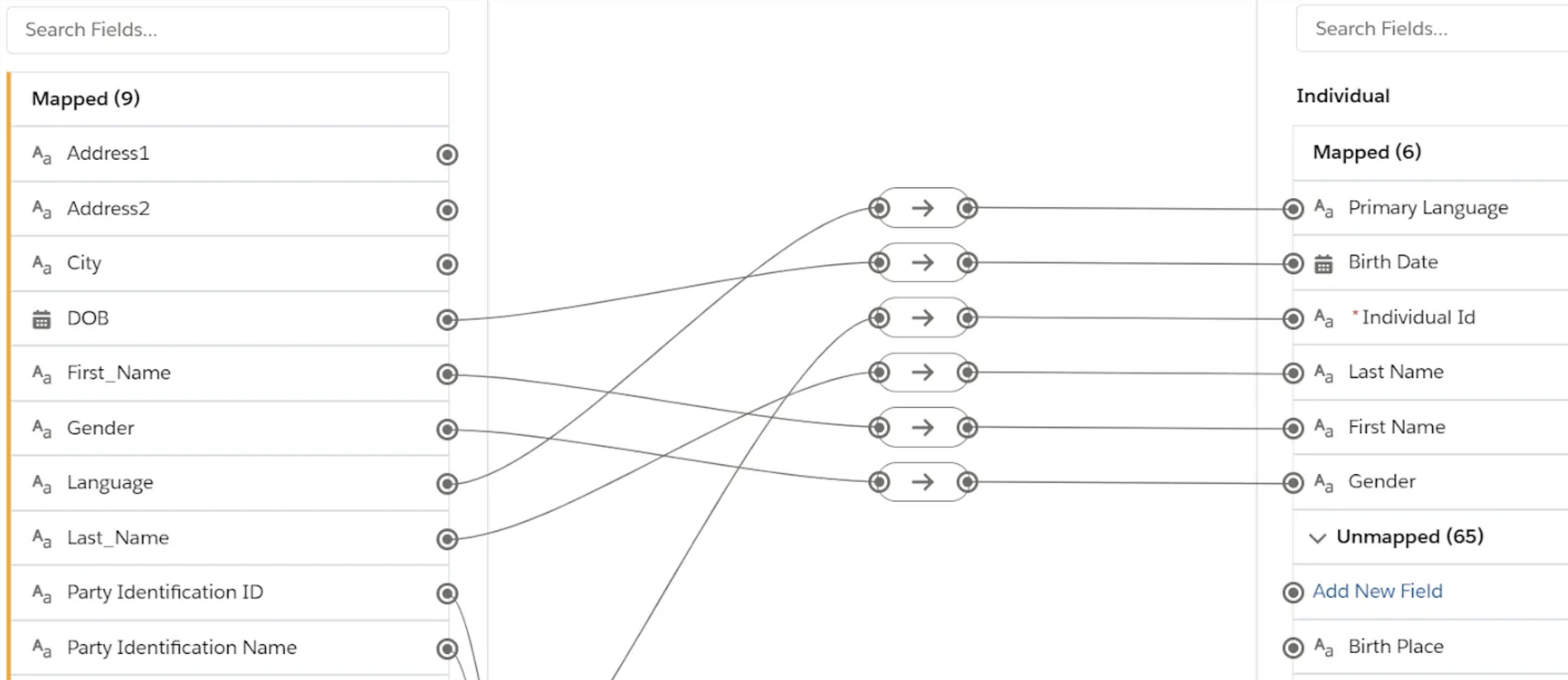
Mapping fields in Data Cloud (source: Salesforce Trailhead)
The result of field mapping is a series of DMOs, each representing a semantic object from the physical objects (DLOs) that provide a virtual, non-materialized view into the data lake. It is also important to note that DLO to DMO field mapping is a one-to-one relationship, that is, you can’t have multiple email addresses or mobile phone numbers for a single individual. For such requirements, it is necessary to split the record into two or more, for example each sharing the same Salesforce Contact Id.
Fully Qualified Keys
An additional platform concept to understand is that Data Cloud employs a unique concept of a Fully Qualified Key or ‘FQK’, which avoids key conflicts when data from different sources are harmonized. An FQK is a composition of a source provided key and a key qualifier, to avoid such conflict scenarios. For example, if an event registration DLO and CRM DLO are both mapped to the Individual DMO, an FQK effectively enables queries to be grouped by data source to allow users to accurately identify, target, and analyze records.
Summary
DMOs are the result of harmonizing multiple data sources into unified views of the data lake. Arguably the most important step in platform design is to make well considered choices at the harmonization stage, as wrong category assignment, inconsistent mapping and incorrect DMO selection can quickly result in technical debt that requires significant effort to remediate. Applying a methodical approach to data mapping, investing in authoring a comprehensive data dictionary, and making informed decisions in this implementation stage will help ensure that harmonized data from different data sources is accurately interpreted.

