

Credits power usage in Salesforce Data Cloud — every time you perform an action in Data Cloud, credits are consumed. Credit consumption is based on different actions performed in the platform, where the actual consumption rate is based on the platform feature, the complexity of that feature, and ultimately the underlying compute cost of the feature. As platform usage increases over time, credits will decrement. Data Cloud customers can purchase additional credits based on their platform usage.
Data Cloud Pricing Model
There are three discrete components in the platform’s pricing model, which include:
- Data Storage: Records stored in data model (in terabytes)
- Data Services: Data Service credit model based on usage
- Add Ons: Optional features including Data Spaces, Advertising Audiences, Activations, and Segmentation
Storage, services and add-on entitlements vary by platform edition.
Data Service Credits
Every platform action has a corresponding compute cost. Whether the action is connecting, ingesting, transforming or harmonizing data, these processes consume ‘data service credits’. Consumption can be broadly categorized into connect, harmonize and activate categories. Each category includes multiple services and the consumption rate varies by service, as outlined in the table below.
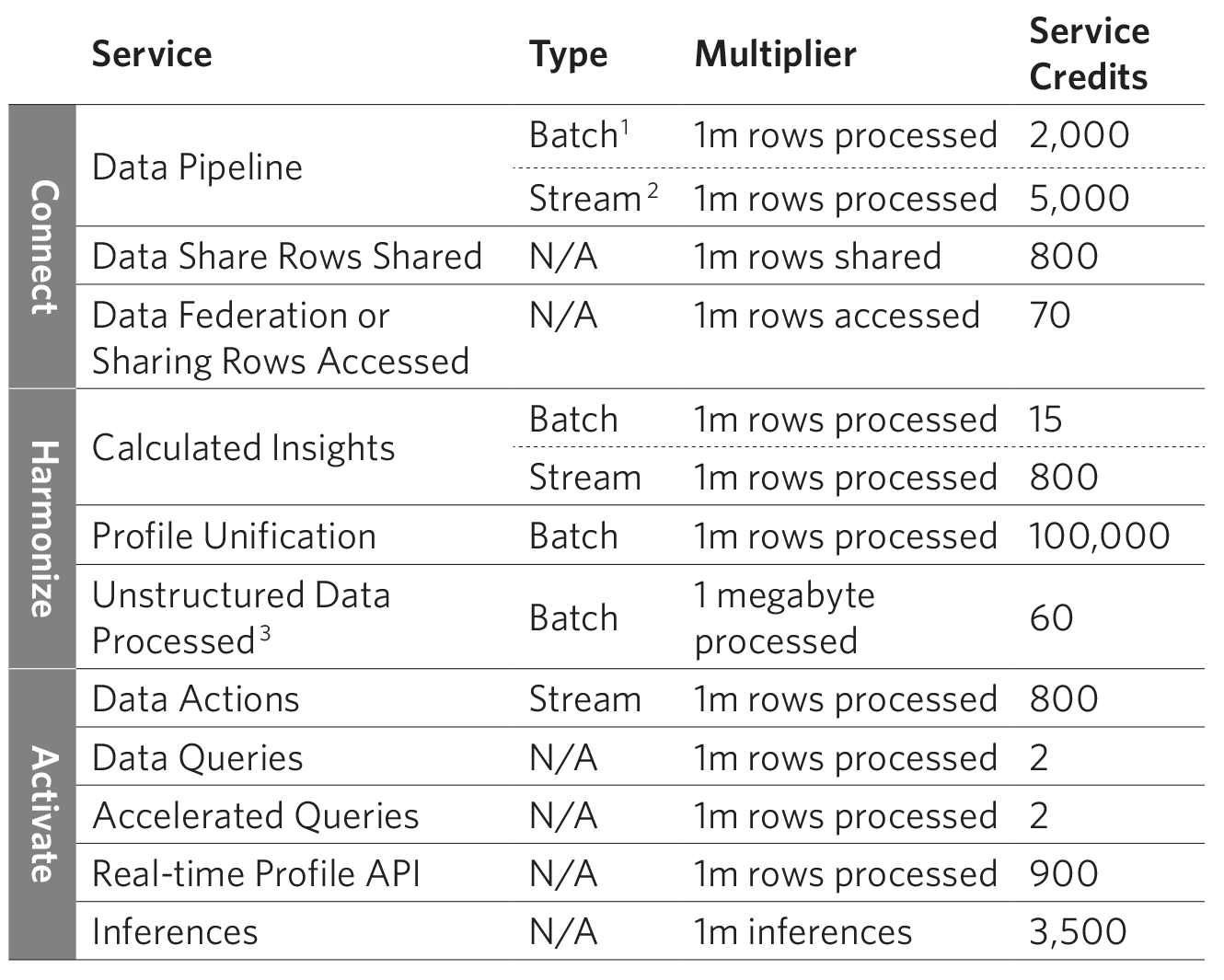
Notes
1. Both data transforms are considered as Batch Data Pipeline usage type.
2. Streaming data transforms are considered as Streaming Data Pipeline usage type.
3. Unstructured Data Processed refers to data ingested into the Data Cloud Vector Database
For example, consider the following use case:
- A data stream imports 1m Contact records from Salesforce CRM
- Data transformation is applied to all ingested Contact records
- The Salesforce Interactions SDK imports 2m cart interaction engagement events from an ecommerce website
These actions result in the following data service credits being consumed:
- Ingest 1m Contact records using batch data pipeline: 2,000 credits
- Data transform 1m Contact records: 2,000 credits
- Ingest 2m cart interaction engagement events using streaming data pipeline: 10,000 credits
The total data service credit consumption for this scenario is 14,000 credits.
Segment and Activation Credits
In addition to data service credits, ‘segment and activation credits’ are consumed based on rows processed in order to publish a segment and rows processed to activate segments (with or without related attributes) as outlined in the table below.

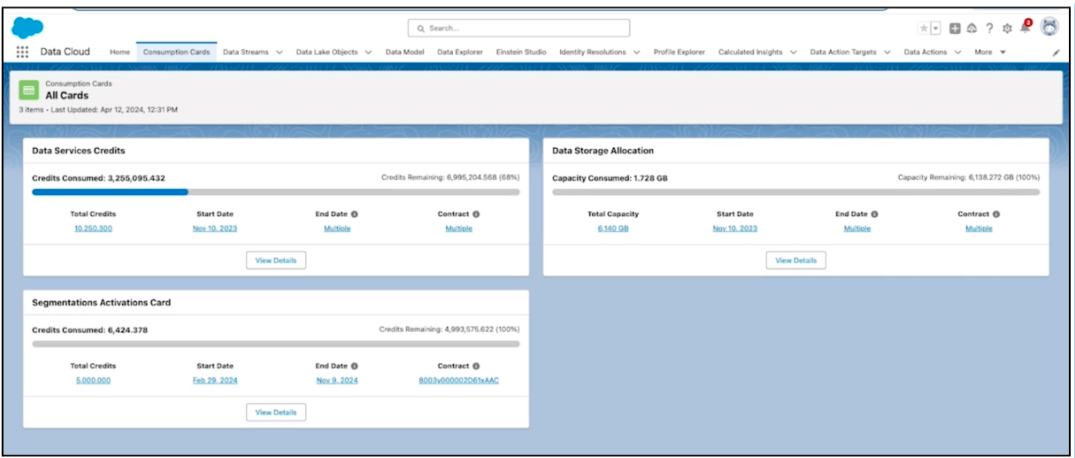
Monitoring Consumption
In order to review credit and storage consumption, Data Cloud users currently have to request a consumption report from their Salesforce Account Executive. However, a new Digital Wallet feature in Data Cloud (introduced in the Summer ’24 Release) will include a Digital Wallet feature, where Data Cloud users can monitor credit and storage consumption in the platform, in addition to reviewing credit consumption trends over time by usage type.
Considerations
It’s important to consider the pricing model and the resulting credit consumption for platform use cases. At a high level, consider the following factors:
Connect
Streaming ingestion incurs significantly higher costs than batch ingestion, so validate if the platform use cases actually require near real-time data, or if batch ingestion will suffice.
Store
Review the number of data streams required and their applicable storage. Start by importing a sample data source and assess the applicable storage size to estimate data storage usage, based on estimated records for each data stream.
Harmonize
Processing records to create unified individual profiles uses the highest rate multiplier, so ensure you are only importing active profiles — consider excluding inactive customers.
Activate
Determine what actions need to be completed to operationalize the data. Multiple actions can be performed in order to activate an individual or unified individual profile, for example segmentations, calculated insights, data actions and activations. Identify which specific actions are required for data activation.
Best Practices
While platform actions consume credits, there are several best practices which you can adopt to help control credit consumption and ensure that credits are not consumed unnecessarily.
Ingestion
Only import the data required to fulfill segmentation, identity resolution, and analytics use cases. For engagement and transaction data, consider the required lookback period for analytics and activation use cases. For example, 9 months of transaction data may be sufficient for certain consumer use cases, so there’s no need to ingest older transaction data. Additionally for batch ingestion, choose incremental refresh instead of full refresh where possible, to limit the number of rows processed.
Data Transformation
While batch transforms facilitate complex calculations on unstructured ingested data, these transformations result in a compute cost. Where possible, prepare or pre-transform data for ingestion using available ETL tools.
Batch Calculated insights
When multiple batch calculated insights are used for the same DMO, consider creating a single multi-dimensional calculated insight instead of separate calculated insights with individual dimensions, to reduce the number of underlying data rows processed. Additionally, ensure the calculated insight is refreshed according to the underlying data used for attributes and measures — if the underlying data only changes weekly, then there is no need for the calculated insight to be refreshed daily. And when a calculated insight is no longer used, then disable it.
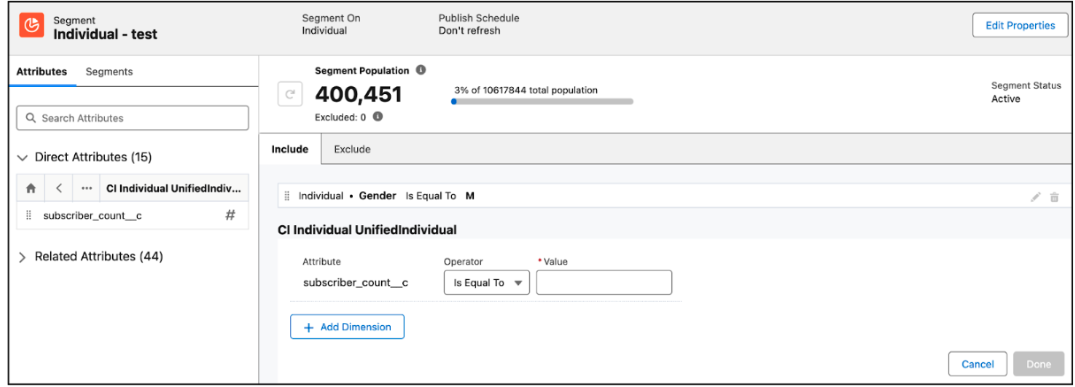
Segmentation
Typically, segmentation is the largest area of credit consumption used in the platform. Segments should be designed with a goal to minimize the amount of rows processed. Ensure you apply the optimal lookback period on engagement data — by default, the platform applies a two year lookback on engagement data, so if you don’t specify a filter, then all related engagement records for the past two years will be processed. If a use case requires a shorter lookback period, for example, individuals who have opened an email in the past six months, then specify a filter in the segmentation canvas.
Consider using nested segments to limit the amount of records processed. Nested segments provide the option to either refresh when the parent segment is refreshed, or use existing segment members from the nested segment. If the segment updates infrequently, for example, to determine “customers who have spent more than $10,000”, then those segment members can be used by a parent segment, without needing to refresh both segments at the same time.
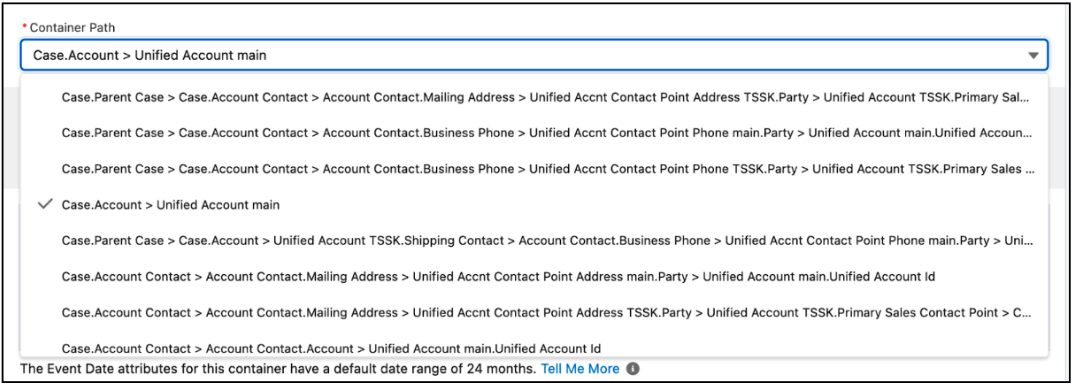
When creating a segment filter to filter on a single attribute, merge containers to a single container where possible, as when multiple containers are used to filter on the same related attribute, multiple subqueries are created to combine the result-set of both subqueries and de-duplicate them, which impacts the total number of records processed. Additionally, when adding related attributes to a container, if there are multiple paths available, choose the shortest path to the DMO as indicated below.
While segments can be refreshed every 12 or 24 hours (or 1 and 4 hour schedules for rapid publish segments), certain use cases may require segments to refresh based on a condition, for example, when a specific data stream refreshes, or when an identity resolution ruleset is published. For these scenarios, a Flow can be used to refresh the segment, triggered by another platform action. In turn, this can be used to ensure segments are not refreshed unnecessarily.
When publishing segments, regularly check that segment member counts for activations are not zero, as empty or invalid segments still require records to be processed. Additionally, deactivate segments when they are no longer required, for example, a segment which was created for a specific promotion.
When segmenting on a Profile DMO, use calculated insights in a segment to reduce the amount of credits required to process based on a metric, for example, number of email opens or a particular age group. In turn, this will reduce the amount of records to be processed to create the segment.
Activation
Similar to segmentation, activations should be designed with a goal to minimize the amount of rows processed. Additionally, when creating an activation for Marketing Cloud Engagement, SFTP or file storage activation targets, you can choose two refresh types: full or incremental. A full refresh updates all records in the segment during activation, whereas an incremental refresh updates only the records that were changed since the last refresh. Choose an incremental refresh where possible, to limit the amount of records processed. Additionally, regularly deactivate any activations that are no longer required.
Identity Resolution
Identity resolution (or profile unification) consumes the highest amount of data service credits. Any change to a ruleset requires a full refresh. Begin by ingesting a sample set of profile data to validate the match rate is accurate, before ingesting all profile data streams. Review resulting unified profiles and associated attributes by viewing the Unified Link Objects, using Data Explorer and Profile Explorer to validate the unified individual profile results by using fields from your match rule. And while anonymous profiles don’t count toward billable unified profiles, the ‘Is Anonymous’ field on the Individual DMO must be mapped for any data stream that includes anonymous records.
Bring Your Own Lake (BYOL)
When using BYOL data federation to perform zero-ETL (Extract Transform Load) integration where data is directly queried from external data platforms, only share the objects you need from the supported BYOL platform — either Snowflake, Google Big Query, Databricks, or Amazon Redshift — as shared rows consume credits. Additionally, remember that in addition to data service credits in Data Cloud, processing records in external platforms may also incur a compute charge.
Optionally, acceleration in data federation can be enabled while creating a data stream for a BYOL data source, where data is retrieved periodically from the BYOL platform (24 hours by default, which can be changed) and the data is persisted in Data Cloud. In turn, this eliminates the need to access shared rows from the BYOL platform each time data is queried. Note that data federation with acceleration is counted as a batch data pipeline for credit consumption. Enable this option for data streams where attributes do not change frequently.
If the BYOL platform resides in the same AWS region as the Data Cloud org (identified from the Setup page in Data Cloud), then there is no credit consumption for sharing rows accessed.
Summary
Consumption credits are the primary entitlement in Data Cloud and form a key component of the platform pricing model. There are many scenarios when credits could be unintentionally consumed. While some use cases for consumption can be estimated — for example, batch data ingestion — certain events can be more difficult to anticipate, for example, an unexpected uplift in website traffic due to a specific promotion, where streaming ingestion is used to capture website engagement events. As a result, Data Cloud users should use Digital Wallet to monitor consumption diligently and take action when necessary, either by purchasing more credits or investigating consumption trend anomalies.
Need help with Data Cloud? Or just want to chat about how you could be getting more out of your Salesforce org? Get in touch! We love this stuff.

